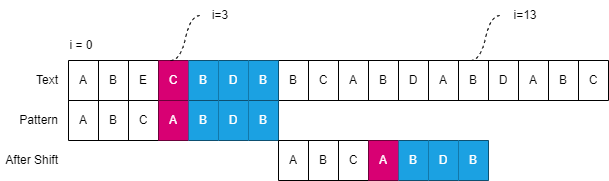
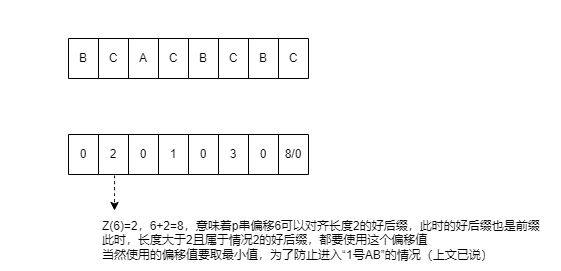由于对齐后 AB 是肯定已经处于匹配状态了,因此直接从上一步的失配位置开始匹配。 此时再次失配,由于 此时的全匹配子串是 AB,是没有重复前后缀的,直接把 P 串右移到失配位置,这和 1 是一个逻辑
通过上面 KMP 算法的演示过程,可以发现,最关键的就是求解根据当前全匹配的子串情况,求解最长的前后缀(也就是第2步的AB),得出了 AB 的长度,P 串的偏移长度也就可以知道了。为什么是最长,可以设想当前的全匹配子串是AABAA, 此时,A与AA都是相同的前后缀,如果对齐 A 的话,后面的 AA 的第一个 A 就会丢失匹配逻辑。
“Partial match” table (部分匹配表)
部分匹配表,也可以理解成失效函数(failure function),为的就是求解上面的问题。我们不可能在匹配过程中去进行求解前后,不难发现,对于固定的 P 串,部分匹配表是完全可求的。例如上面那个例子:
/** * @param {string} haystack * @param {string} needle * @return {number} */ var strStr = function (haystack, needle) { // KMP let pmt = newArray(needle.length).fill(0); for (let i = 1; i < needle.length; i++) { if (needle[pmt[i - 1]] === needle[i]) { pmt[i] = pmt[i - 1] + 1; } else { if (needle[pmt[pmt[i - 1] - 1]] === needle[i]) { pmt[i] = pmt[pmt[i - 1] - 1] + 1; } else { pmt[i] = 0; } } } let i = 0; let j = 0; while (i < haystack.length) { if (haystack[i] !== needle[j]) { // 这里需要判断是否要进行失配偏移,否则会干扰正常的迭代 if (j > 0) { j = pmt[j - 1]; } else { i++; } } else { // 已经匹配到p串最后一位,程序退出 if (j === needle.length - 1) { return i - j; } i++; j++; } } return -1; };
KMP算法-时间复杂度
求解部分匹配表用了O(m),匹配用了O(n),整体时间复杂度为O(n)+O(m)。
Boyer-Moore algorithm (BM 算法)
KMP 算法发布的同年, Robert S. Boyer 与 J Strother Moore 设计了该算法。它不需要对被搜索的字符串中的字符进行逐一比较,而会跳过其中某些部分。
与 KMP 算法不同的是它是从 p 串末尾开始比较的,如果最后一个字符不匹配,那么就没必要继续比较前一个字符。如果最后一个字符未在 P 中出现,那么我们可以直接跳过 T 的 n 个字符,比较接下来的 n 个字符,n 为 P 的长度。如果最后一个字符出现在 P 中,那么跳过的字符数需要进行计算(也就是将 P 整体往后移),然后继续前面的步骤来比较。通过这种字符的移动方式来代替逐个比较是这个算法如此高效的关键所在。
目前大多数的软件查找大多使用该算法。下面来看 BM 算法的过程:
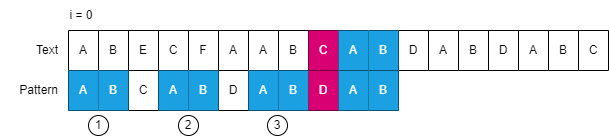
可以发现失配的”S”未曾出现在 P 串中,因此可以把 p 串移动到失配位置后面(”S”不可能与 p 串中的任何一个字母相等)
此时 i 指针的偏移为 8,等于AB的长度(2)+2号AB对齐所需要的偏移(6) = 8 为什么会出现需要移动到 2 号 AB 的情况? 仔细观察可以发现,3 号 AB 无法使用是因为,三号 AB 是相同最长后缀BADBA的后缀,换句话说,因为BADBA才是相同最长后缀,因此它的子后缀(例如:B, BAD, BADB…)全都会陷入 3 号 AB 的情况。
对于任一 i, 如果 Z(i)>0,就意味着:偏移长度i可以对齐Z(i)长度的好后缀,(并且此时好后缀左侧的第一个字符也不相等,也就规避了3号AB的问题)。 与此同时,如果有多个 Z 值相等,应该使用较小的偏移,例如上面的 2号AB的例子,此时不应该对齐 i 较大的1号AB,否则会漏掉匹配机会。
借助 Z 函数,可以填充最终好后缀规则的情况 1。
Z-Algorithm (Z 算法)
而上面这个 Z 函数就是将 p 串翻转后进行 Z-Algorithm(Z 算法),也常常被称为扩展 KMP,感觉和 KMP 没啥关系 😥。Dan Gusfield 在他的书《Algorithms on Strings, Trees, and Sequences》中讨论了 Z 值。尽管有一些争议,但有人声称 Dan Gusfield 是 Z 算法的发明者。Z 值是 Z 算法中的一个重要概念,用于计算字符串中匹配前缀的最长子串的长度。
在 Z 算法 中,对于一个字符串 S={S0,S1,⋅⋅⋅,Sn−1},定义Z(i)表示从位置 i 开始的 S 的后缀Ti={Si,Si+1,⋅⋅⋅,Sn−1}与S的最长公共前缀的长度。
functionbuildGSR(needle) { // 初始化为所有的好后缀情况都偏移到p串后面 const gsr = _.range(needle.length, 2 * needle.length); // 无好后缀,只移动最差的1位 gsr[0] = 1; const z = zReverseFunc(needle); for (let i of _.range(1, z.length)) { if (z[i]) { // 情况1 gsr[z[i]] = Math.min(gsr[z[i]] || Infinity, i + z[i]); } } for (let i of _.range(1, z.length)) { if (z[i] + i === needle.length) { // 此时是一个前缀 // 情况2 for (let j of _.range(z[i] + 1, gsr.length)) { gsr[j] = Math.min(gsr[j], i + j); } } } return gsr; }
functionzReverseFunc(str) { const n = str.length; const z = Array(n).fill(0); let l = 0, r = 0; for (let i = 1; i < n; i++) { // 是否在Z-Box中 if (i < r) { // Z-Box中剩余的长度够Z[i-l] if (z[i - l] < r - i) { z[i] = z[i - l]; continue; } else { z[i] = r - i; } } // 暴力求解 // 这里从后往前取值,避免翻转字符串 while ( n - 1 - (i + z[i]) >= 0 && str[n - 1 - z[i]] === str[n - 1 - (i + z[i])] ) { z[i]++; } l = i; r = i + z[i]; } return z; }
The bad-character rule (坏字符规则)
一张哈希表记录下当出现失配字符时,i 指针需要偏移的值(其实就是该字符到末尾的位置),需要注意的是,p 串重复出现的字符总是需要优先采用靠右的字符去对齐(和 1 号 AB 是一个道理),因此从左往右迭代 p 串,覆盖更新即可。 可以参考这篇 Boyer-Moore: Bad character rule
1 2 3 4 5 6 7 8 9 10
import _ from"lodash";
functionbuildBCR(needle) { const bcr = {}; for (let i of _.range(needle.length)) { const c = needle[i]; bcr[c] = needle.length - 1 - i; } return bcr; }
template <typename PatternChar, typename SubjectChar> int StringSearch<PatternChar, SubjectChar>::BoyerMooreSearch( StringSearch<PatternChar, SubjectChar>* search, base::Vector<const SubjectChar> subject, int start_index) { base::Vector<const PatternChar> pattern = search->pattern_; int subject_length = subject.length(); int pattern_length = pattern.length(); // Only preprocess at most kBMMaxShift last characters of pattern. int start = search->start_;












")
")




")




,这也是常说的假设p串前有虚拟字符(个人感觉挺误导的)")