本篇旨在不断收集归纳图论的各种定理(不详细记录证明过程),以及在计算中的各种实现与应用。
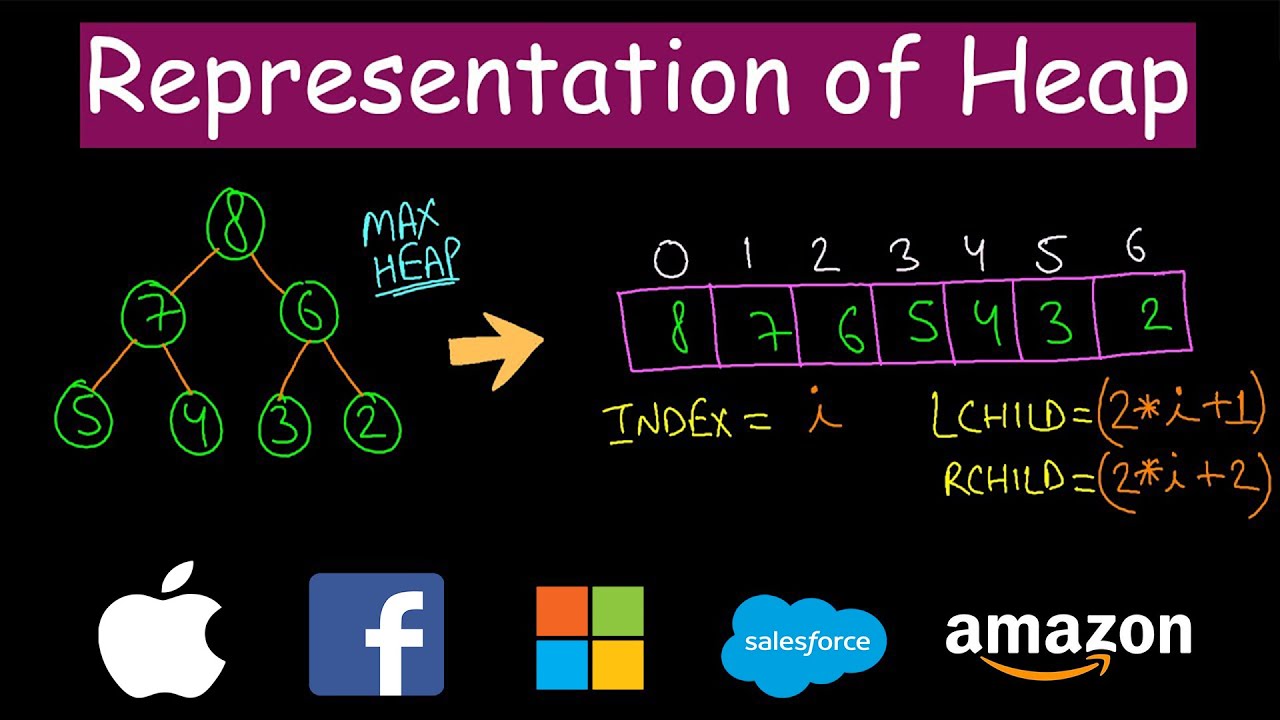
图的表示方法 (数据结构)
邻接矩阵 (Adjacency matrix)
][index(D)] = 1")
邻接表 (Adjacency List)

无向图 (Graph)
无向图就是每条边都没有方向的图。
欧拉路径 (Eulerian path)

对于一个给定的图,怎样判断是否存在着一个恰好包含了所有的边,并且没有重复的路径?这就是一笔画问题。用图论的术语来说,就是判断这个图是否是一个能够遍历完所有的边而没有重复。这样的图现称为欧拉图。这时遍历的路径称作欧拉路径(一个环或者一条链),如果路径闭合(一个圈),则称为欧拉回路。
定理一
- 连通的无向图 𝐺 有欧拉路径的
充要条件是:
𝐺中奇顶点(连接的边数量为奇数的顶点)的数目等于0或者2。- 连通的无向图 𝐺 是欧拉环(存在欧拉回路)的
充要条件是:
𝐺中每个顶点的度都是偶数。
定理二
如果连通无向图 𝐺 有 2𝑘 个奇顶点,那么它可以用 𝑘 笔画成,并且至少要用 𝑘 笔画成。
哈密顿路径 (Hamiltonian path)
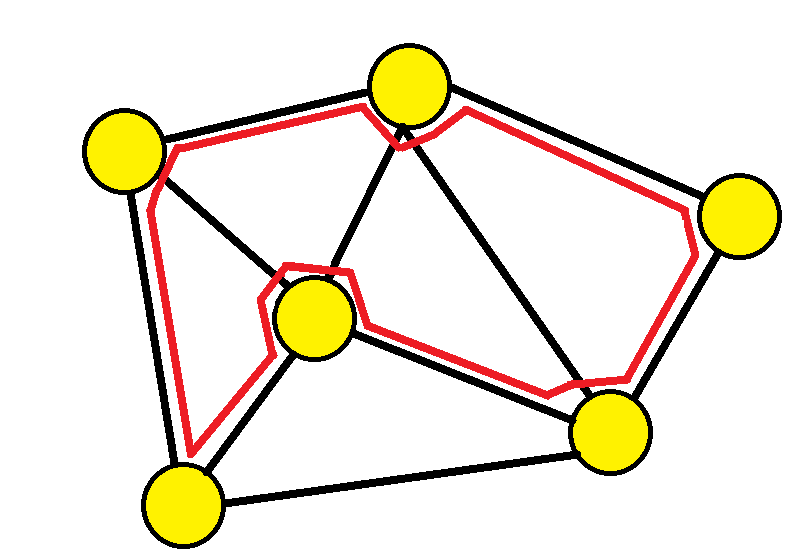
哈密顿路径是在无向图或有向图中,恰好能将图中所有顶点各拜访一次的路径。与之相近的概念为哈密顿环,即该路径在拜访完图中所有顶点后会回到出发点,而构成一个环。要确定图中是否存在哈密顿路径或哈密顿环的问题称为哈密顿路径问题,这个问题是一个NP完全的问题(指数级别的时间复杂度)。
哈密顿路径要求通过所有顶点(哈密顿路径问题)而欧拉路径要求通过所有边(一笔画问题)。
有向图 Directed graph
 有向图,顾名思义就是每条边都有方向的图。
有向图,顾名思义就是每条边都有方向的图。
有向无环图 (Directed acyclic graph)
在图论中,如果一个有向图从任意顶点出发无法经过若干条边回到该点,则这个图是一个有向无环图(英语:Directed Acyclic Graph,缩写:DAG)。即使图被分割成多个连通分量,只要每个分量都是有向无环的,整个图仍然可以是DAG。
拓扑排序
有向无环图的拓扑排序为所有边的起点都出现在其终点之前的排序。能构成拓扑排序的图一定没有环,因为环中的一条边必定从排序较后的顶点指向比其排序更前的顶点。基于此,拓扑排序可以被用来定义有向无环图:当且仅当一个有向图有拓扑排序,它是有向无环图。一般情况下,拓扑排序并非唯一。
有向无环图仅仅在存在一条路径可以包含其所有顶点的情况下,有唯一的拓扑排序方式,这时,拓扑排序与它们在这条路径中出现的顺序相同。
卡恩算法 (Kahn’s algorithm)
卡恩于1962年提出了该算法,该算法用于计算有向图的拓扑排序。
卡恩算法的思路很简单,不断的挑选入度为0的节点并将其移出图(也就是更新点边集),再重复过程即可得到一个拓扑排序。
如上图的例子,初始扫描生成入度表(用hashMap或者数组存储都可以),生成入度表的同时把入度为0的顶点加入队列(循环的初始运行条件)。
初始的入度表为: A : 2, B : 1, C : 1, D : 2, E : 0, F : 0
初始的队列为: [E, F]
循环的设计很简单,只要队列里还有顶点,就需要一直循环。
E出队列,检查邻接表,更新A的入度(也就是入度-1),如果发现更新入度后该顶点的入度为0,则把顶点加入队列。
与此同时,将出队列的元素记录下,也就是最终的拓扑排序结果。
 F出队列,检查邻接表,更新A,B的入度,A,B的入度为0,把A,B加入队列。
与此同时,将F记录下。
F出队列,检查邻接表,更新A,B的入度,A,B的入度为0,把A,B加入队列。
与此同时,将F记录下。退出循环,拓扑排序的结果为 [E, F, A, B, C, D]。
根据拓扑排序的定义,最终循环退出后的拓扑排序的长度不等于顶点数,则存在环。
练个手:207. 课程表
1 | /** |
深度优先算法
深度优先算法也可以用于计算拓朴排序,深度优先搜索以任意顺序循环遍历图中的每个节点。若搜索进行中碰到之前已经遇到的节点,或碰到叶节点,则中止算法并回溯的将未曾访问的节点压倒栈中(也就是最终的拓扑排序)。
检测环算法
根据上面的卡恩算法可以看出一点,如果初始没有入度为0的节点,那么循环就不会执行,拓扑排序的结果为空,因此一定存在环。
因此有:
所有顶点的入度都不为0的有向图中一定存在环。然而反过来却不然,因此只能证明其充分性(好像没啥用)。
如果是链表方式的图,则可以使用Floyd判圈算法,也就是快慢指针。
加权图 (Weighted graph)
 是指每条边都对应有一个数字(即“权重”,weight)的图。根据具体问题,权重可以表示诸如费用、长度或容量等意义。这样的图会出现在最短路径问题和旅行商问题等问题中。
是指每条边都对应有一个数字(即“权重”,weight)的图。根据具体问题,权重可以表示诸如费用、长度或容量等意义。这样的图会出现在最短路径问题和旅行商问题等问题中。
最短路径 (Shortest path)
最短路径问题是图论研究中的一个经典算法问题,旨在寻找图(由结点和路径组成的)中两结点之间的最短路径。算法具体的形式包括:
确定起点的最短路径问题 (single-source)
确定起点的最短路径问题,也叫单源最短路问题,即已知起始结点,求最短路径的问题。
迪杰斯特拉算法 (Dijkstra’s algorithm)
迪杰斯特拉算法是计算机历史上最著名的算法之一,得力于其广泛的应用基础(如GPS导航等)。
该算法只能用在权重为正的图中,因为计算过程中需要将边的权重相加来寻找最短路径。
")
由于该算法属于特别经典的算法,可以快速求出定源到每个可达到的点的最短(或最长)路径。一般使用优先队列来实现。
优先队列优化的迪杰斯特拉算法
传统的算法使用两个集合(已访问的未访问的)。因此,在更新最短路后将该节点的所有邻接节点的距离更新后,寻找未访问节点集合中离源点最近的时间复杂度为。
而这部分是可以使用优先队列(堆)优化的,优化后时间复杂度为单次出堆的时间:。这也是最常用的写法。
以上图为例,算法是这样进行的。代码可以在这里测试
1 | // 邻接表 |
初始化距离数组,需要 O(V) 的时间。每条边都有可能被入堆、出堆一次,需要|E|log|E|的时间,因此总体时间复杂度为。
贝尔曼-福特算法 (Bellman–Ford algorithm)
由于迪杰斯特拉算法无法正确处理带负权的图,因此该算法被提出。原理是对图的所有边进行次松弛操作,得到所有可能的最短路径。
为什么是松弛|V|-1次?
简单来说就是从源点到一个点的最短路最极限的一种情况的路径需要经过全部的点,也就是需要松弛|V|-1次,这样,我们执行|V|-1次就可以保证所有的点都松弛到最佳的情况,如果执行了|V|-1次后还能继续松弛,那就说明图中有负权环。缺点是时间复杂度过高,高达。但算法可以进行优化提高效率。比如在循环中设置判定在某次循环中没有进行松弛时,就已经得到了最短路径(也不需要进行负环判定)。
最短路径快速算法 (Shortest Path Faster Algorithm)
该算法是带有队列优化的Bellman-Ford 算法,该算法和上面的优先队列优化的迪杰斯特拉算法很相似。
1 | procedure Shortest-Path-Faster-Algorithm(G, s) |
SPFA算法并不能处理负环问题,在存在负环的图上使用该算法会导致无限循环。
解决方案:
添加计数器: 在 SPFA 算法中,可以使用一个计数器来记录每个节点入队的次数。如果一个节点入队次数超过了节点数量,则说明存在负环。
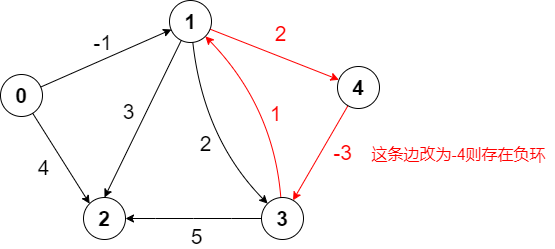
以上图为例,算法是这样进行的。代码可以在这里测试
1 | // 邻接表 |
SPFA 算法的最坏时间复杂度为。在最坏情况下,每个顶点可能被加入到队列中多次,最多可能被加入|E|次,因为每个顶点最多有|E|条边与其相连。SPFA 算法的实际运行时间通常比要快,尤其是在稀疏图中。当图中存在负权回路时,SPFA 算法无法保证能够找到最短路径,并且可能陷入死循环。
确定起点与终点的最短路径问题 (single-pair)
A*搜索算法 (A* search algorithm)
A*搜索算法是一种在图形平面上,有多个节点的路径,求出最低通过成本的算法。常用于游戏中的NPC的移动计算,或网络游戏的BOT的移动计算上。
设想这样一种场景,你需要去往东北方向的村子并试图找到最短的路。使用上面几种算法时,都是基于遍历的算法,于是往南的村子的最短路径也被“顺便”算出来了,这种计算明显是可以优化的计算。也就是启发式的搜索。
在此算法中,如果以表示从起点到任意顶点𝑛的实际距离,表示任意顶点𝑛到目标顶点的估算距离(根据所采用的评估函数的不同而变化),那么A*算法的估算函数为:
这个公式遵循以下特性:
- 如果为0,即只计算任意顶点𝑛到目标的评估函数,而不计算起点到顶点𝑛的距离,则算法转化为使用贪心策略的最良优先搜索,速度最快,但可能得不出最优解;
- 如果不大于顶点𝑛到目标顶点的实际距离,则一定可以求出最优解,而且越小,需要计算的节点越多,算法效率越低,常见的评估函数有——欧几里得距离、曼哈顿距离、切比雪夫距离;
- 如果为0,即只需求出起点到任意顶点𝑛的最短路径,而不计算任何评估函数 ,则转化为最短路问题,即Dijkstra算法,此时需要计算最多的顶点;
全局最短路径问题 (all pairs)
也叫多源最短路问题,求图中所有的最短路径。
弗洛伊德算法 (Floyd–Warshall algorithm)
Floyd-Warshall算法的原理是动态规划。
设为从到的只以集合中的节点为中间节点的最短路径的长度。
有如下的状态转移:
1 | let dist be a |V| × |V| array of minimum distances initialized to ∞ (infinity) |
最小生成树 (Minimum spanning tree)
最小生成树(英语:Minimum spanning tree,简称MST)是最小权重生成树(英语:Minimum weight spanning tree)的简称,是一副连通加权无向图中一棵权值最小的生成树。
 之前写的使用并查集的克鲁斯克尔算法就是用于解决这一问题的。
最小生成树的算法很多,以后有机会在更新。。。(手都写酸了)
之前写的使用并查集的克鲁斯克尔算法就是用于解决这一问题的。
最小生成树的算法很多,以后有机会在更新。。。(手都写酸了)